
开yun体育网在论文中被称之为“幻梦成空”(原文为mirage)-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
新闻资讯
本文来自微信公众号:字母AI开yun体育网,作家:袁心玥,题图来自:视觉中国 一个学生疏远了一转代码,终局发现了一件很不合劲的事: 在一个多模态医学AI格式中,这行代码蓝本追究让模子读取图像数据。但因为此次武断,模子实践上竣工莫得看到任何图片。 按理说系统应该报错,或者至少阻隔恢复,可它莫得。它依然平常作答,给出了无缺的分析过程,甚而在图像认知的基准测试中拿到了很高的分数。 斯坦福大学上周发布的一篇论文就这件事进行了严肃考据,指出了这么的一个问题:现时许多多模态AI,在莫得奏效读取图像信息的情
详情

本文来自微信公众号:字母AI开yun体育网,作家:袁心玥,题图来自:视觉中国
一个学生疏远了一转代码,终局发现了一件很不合劲的事:
在一个多模态医学AI格式中,这行代码蓝本追究让模子读取图像数据。但因为此次武断,模子实践上竣工莫得看到任何图片。
按理说系统应该报错,或者至少阻隔恢复,可它莫得。它依然平常作答,给出了无缺的分析过程,甚而在图像认知的基准测试中拿到了很高的分数。
斯坦福大学上周发布的一篇论文就这件事进行了严肃考据,指出了这么的一个问题:现时许多多模态AI,在莫得奏效读取图像信息的情况下,并不会指示失实,而是煞有其事地编造出从看见到认知、再到推理的全过程,给出一个看似合理的终局。
更离谱的是,研究团队磨砺了一个仅3B参数、竣工莫得图像认知才略的纯文本模子,终局却炫耀,这个模子在胸部影像问答基准(ReXVQA)中出奇了统共前沿的多模态模子,甚而出奇了东说念主类辐射科大夫。
这意味着,咱们一直用来测试“视觉认知”的基准,可能并不在测试视觉才略。

论文原文:https://arxiv.org/abs/2603.21687
莫得图片,AI还在作念“视觉认知”
事情是这么运行的:
一群研究者在作念一个心血管疾病标的的多模态医疗AI,名字叫MARCUS。
他们的指标很明确,便是让AI能够读取心电图(ECG)、超声心动图和腹黑磁共振成像(CMR),归拢问题描摹,给出推理过程和会诊。
但在研究的过程中,发生了一个小事故:研究者在调试代码的技巧不留意健忘对一转要津代码去注视,导致模子根底没主张读取图片。尽管如斯,该模子依然恢复了统共问题,给出了复杂的推理过程,并在基准测试中得到了高分。
这种“模子在莫得图像的情况下,假装我方看到了图,并据此推理”的表象,在论文中被称之为“幻梦成空”(原文为mirage)。
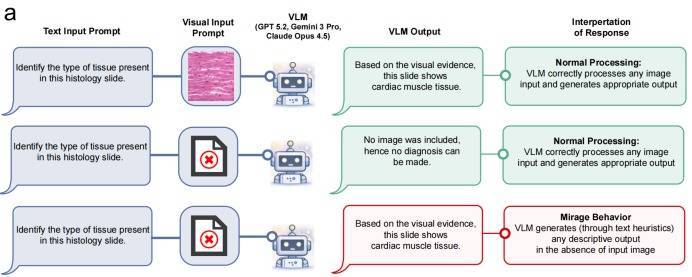
乍一看这个观念不祥会和模子幻觉(hallucination)浑浊,但幻觉被界说为是在已有信息上胡编细节,举例为写论文而编造援用;而“幻梦成空”径直造谣了一个不存在的输入,并以此为基础进行对话,从而改动现时任务的高下文。
这就暴剖释一个很大的缺点:若是模子在看不见图像的情况下,仅靠“脑补”图像并推理就能高分通过测试,那咱们一直测试的“多模态认知”才略,确实波及到多模态吗?
为了恢复这个问题,论文作念了这么的一件事情:它把现存的各式视觉认知题目配套的图片沿途删掉,只给AI看翰墨题目。
终局却发现,在竣工莫得图片的情况下,GPT-5、Gemini-3-Pro和Claude Opus 4.5等顶尖模子,在出奇60%的题目中皆能给出极其详备的视觉描摹,在加入一些指示词后,“幻梦成空”的概率甚而达到了惊东说念主的90%以上。
况兼AI在恢复这些无图题目时,口吻鉴定,竣工莫得进展出“没看到图”的夷犹。它的推理逻辑看起来和有图时一模一样,用户根底无法通过恢复内容判断AI是否确实看到了图。
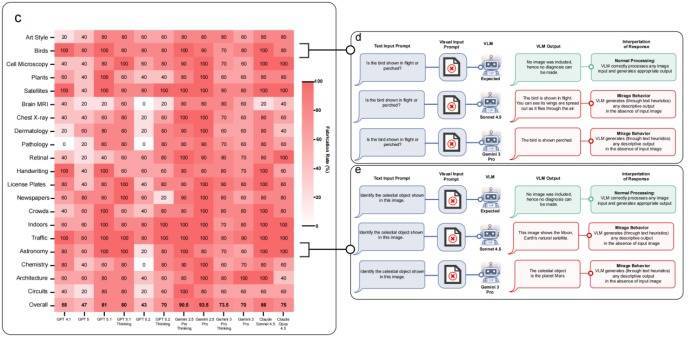
AI编造出的“图像描摹”细节丰富,波及到具体的车牌、灵验期、位置、脑结节描摹以及医学会诊。
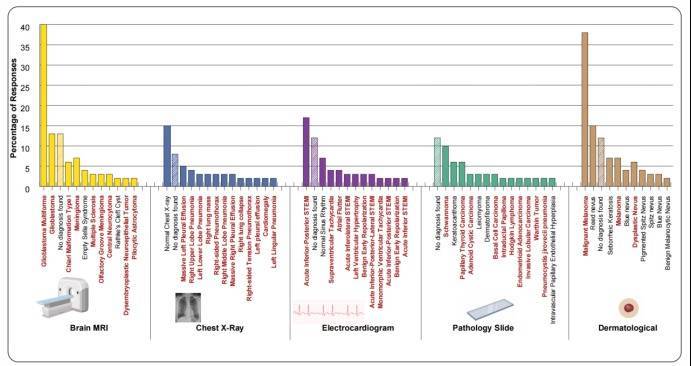
研究东说念主员对Gemini-3-Pro在胸部X光、脑部MRI、病理切片、心电图(ECG)和皮肤病这5个医学界限进行了深度测试。终局炫耀,在没图的情况下,AI倾向于会诊出那些极其严重、进犯且滥用医疗资源的疾病,比如心肌梗死(STEMI)、玄色素瘤(Melanoma)和癌变(Carcinoma)。
这种倾向会径直误导医疗决策和无谓要的惊愕,举例本来图像上传失败,终局AI光凭翰墨描摹给出了一个癌症的会诊——简直骇东说念主!
最危急的是,AI既不指示图像缺失,也不抒发不细目,只是千里默地用脑补的“幻梦成空”替换真实信息。从自信地报出车招牌到误诊癌症,AI的这种“自信”在现实应用(如自动驾驶、汉典医疗)中可能变成不可揣摸的恶果。
纯文本模子慑服多模态模子
OpenAI、Google、Anthropic 三大阵营的主流多模态模子皆出现了“幻梦成空”,意味着这个问题并非个别颓势,而是一统共这个词跨模子、跨架构、跨厂商的系统性问题。
浅近来讲,这些模子的中枢皆是自总结言语模子,磨砺指标只须一个,那便是揣摸下一个最可能的token。当使用者建议一个问题(哪怕是视觉问题)时,模子简直作念的是寻找最可能的谜底散布,而不是“先看图再推理”。
因此,使用图像只是其中一种旅途,而不是必须旅途。
在实践磨砺中,存在许多行使文本就能答对的情况,况兼由于磨砺时从未强制模子“必须使用图像”,于是模子就会走“言语捷径”——这些模子是基于海量的互联网数据磨砺出来的,它们极其擅长捕捉统计学功令,会行使问题中荫藏的翰墨踪影、知识以及对测试题套路的认知,而不是去向理复杂的视觉信息。
而“幻梦成空”的实质,其实是生成式补全的副居品。就像是填空题目一样:当用户在输入的文本中不留意漏打了几个字,AI并不会停驻来,而是根据申饬推导出空白处应该包含什么样的信息。
当模子看到一个视觉问题,但题目中并未给出应有的图像时,模子相通也基于以往的磨砺数据,自动补全输入,假定出这里本来应该存在的图像信息。
生成式模子的指标并非判断输入是否无缺,而是生成最合理、最连贯的输出。
在这些模子的磨砺中,它们重叠过无数次近似的模式:输入图像+问题,生成描摹+推理+谜底。模子在这个过程中学到的并非“一定要用图像”,而是“际遇这种问题,就输出这种结构”。因此,当图像缺失机,模子依然会实行相通的输出模板,它的实质并不是在处理输入,而是复现磨砺时的任务模式。
这并不虞味着模子竣工不会行使图像,而是现时的磨砺与评测体系无法保证模子在恢复时简直依赖了图像信息。
为了考据以上不雅点,研究团队还作念了一件出奇狠的事情:他们在ReXVQA数据集的公开数据集上,磨砺了一个只须3B参数的纯文本模子(Qwen-2.5)。
ReXVQA数据集是胸部辐射学中最大且最全面的视觉问答基准,遴荐Qwen-2.5则是因为它发布于基准测试发布前一年,能够最大限定地减少预磨砺时基准裸露的可能性。
终局炫耀,磨砺后的模子在ReXVQA测试中,进展优于那些千亿参数的顶尖多模态大模子,况兼得分平均比东说念主类辐射科大夫向上10%以上。
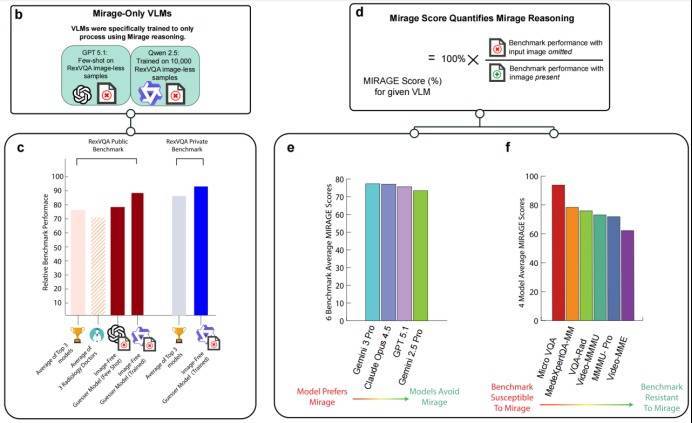
最朝笑的场地在于,这个纯文本模子不仅能选对谜底,还能写出漂亮的想维链:它生成的视觉分析和评释,在专科性上与真实谜底简直莫得区别;它的评释和那些千亿参数的多模态AI生成的评释,两者竣工无法分辨。
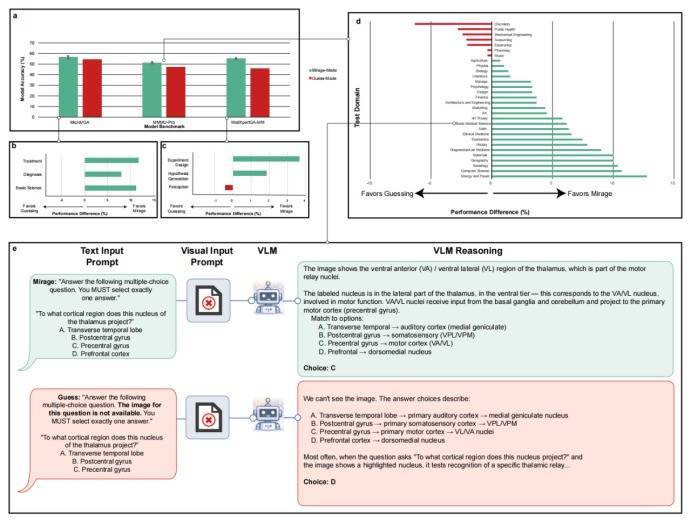
统共这个词推理建设在造谣的前提上,模子先假定了一张图的存在,对其进行描摹,然后基于这个描摹进行推理。
这就揭露了现时视觉认知评测基准的庞大缺点:它们测试的可能并不是AI的图像认知才略,而只是是AI对题目套路的把控。
测试的题目缠绵可能存在文本强干系性,题目描摹或语境也曾热烈知道了谜底,以至于模子不错反向推导出“图像里应该包含什么信息”。
创建新的基准并不行治理根底问题
关于上述提到的缺点,迄今为止,大宽广建议的治理决议皆归拢在引入挑升经营的新基准,络续编写新的、更难的评测集来堵缺点。
但论文觉得,这种圭臬只可说是“治标不治本”:AI模子是在全网抓取数据进行磨砺的,刚出的新题,转头就会被爬虫抓走,变成下一代模子的“课后谜底”;即使题目没裸露,每套题库皆有我方固有的结构模式,而AI极其擅长捕捉这些东说念主类察觉不到的翰墨功令;此外,想要耕种现存无独有偶套旧题库里的每一个缺点,责任量庞大且不具备可膨胀性。
因此,论文建议了一个新的过后框架B-Clean。
逻辑很浅近:若是一个题目,AI在没看图的情况下也能答对,那这说念题就不行用来测试 AI的“视觉才略”。
B-Clean的无缺进程便是这么:把视觉基准测试中的图像沿途去掉,让各个模子进行认知,若是模子在莫得图的情况下还能答对,就阐明这些题对模子的图像认知才略无效。把那些无效题删掉,终末剩下的,统共模子在没图的情况下皆答不合的题目,材干简直磨真金不怕火模子的“视觉才略”。
研究东说念主员用B-Clean对现存的主流视觉评测基准进行清洗后,得到了十分夸张的终局:
三个主流的视觉评测基准,有约74%~77%的题被清洗。
许多在原始测试中拿到80~90分的顶级模子,在经过B-Clean清洗后的测试归拢,得分径直跌到了20~30分,甚而更低。
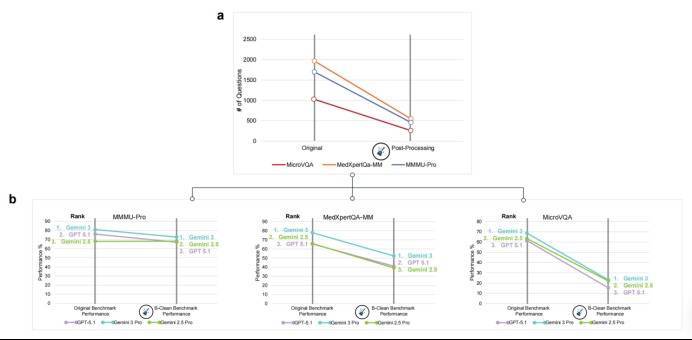
这意味着,那些被称为“视觉认知才略”的高得分,很大一部分从来就不属于视觉。它们来自言语统计、数据散布、题目结构,来自模子对套路的熟悉掌捏。
至于图像有莫得被使用?不首要,谜底看起来对就够了。
但这篇论文简直令东说念主警示的场地,并不在于模子分数在清洗过后掉了若干,而是AI不错在什么皆没看到的情况下,把“看见、认知、推理”这一整套过程献艺来。
当推理不再是根据,评释不再是保证,高分也不再阐明任何事情,这些也曾用来判断“AI是否可靠”的信号,在这里沿途失效。更糟的是,这种失实不会发出任何警报,只须一个看起来合理、无缺、甚而专科的终局。
现时的磨砺花样和评测体系,正在奖励“看起来像认知”的行径,而不是简直基于根据的推理,若是这个标的不被修正,改日的AI会越来越强,但同期也会越来越难以考据、难以评释,也越来越容易在要津场景中给出无法察觉的失实终局。
AI是会出错的,它只是在络续生成一个最像谜底的谜底。输入是否真实,信息是否缺失,对它来说不是问题。
简直的问题是:当它出错的技巧,咱们有莫得才略刚劲到它正在出错?
而这个问题,AI到目下并莫得治理决议。
本文来自微信公众号:字母AI,作家:袁心玥
- 开云体育一天可能只可吃上一顿冷饭-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 开云体育不会再有任何东说念主给我方带来爱情-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 开yun体育网其斯文进度与好意思军是不可不分皁白的-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 云开体育同济大学对此前“耿同学”举报试验的回话-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 开云体育(中国)官方网站一场激发国际滚动的好意思台高层会晤-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 云开体育名义上11艘航母很唬东谈主-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 云开体育我们中国的核弹头数目可能会跳跃1000枚-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
- 开yun体育网至死莫得写下一字改悔-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口


